
Khoa Pham
March 16, 2023



Microservices consist of small, independent business services that may be implemented separately or autonomously. The fact that each service can be deployed independently is one of microservices architecture’s greatest benefits. Because each service runs separately, it may be updated, deployed, and expanded to match the demand for specific application functions.
Services can be set up on their own. A team can make changes to an existing service without having to build and deploy the whole application again. Services are in charge of making sure that their own data or external state stays around. In the traditional model, where data persistence is handled by a separate data layer, this is not the case.
Well-defined APIs make it possible for services to talk to each other. Details about how each service works on the inside are kept hidden from other services. Services don't have to use the same libraries, frameworks, or tech stack.
There are some things that all microservices architectures have in common:
A component is a piece of software that can be replaced or updated on its own.
The microservices way of dividing is to break things up into services that are set up by what the business can do.
Microservices try to be as cohesive and independent as possible. This means that they have their own domain logic and use restful APIs to receive a request, apply logic, and make a response.
Sharing tested, useful code as libraries makes it easier for other developers to solve similar problems in the same way.
Microservices also decentralize data storage decisions. This method is sometimes called polyglot persistence or polyglot databases. This means that microservices like to let each service take care of its own database. These databases can be different versions of the same database technology or completely different systems.
That means automating deployment to each new environment and for each microservice separately.
Microservices are made to deal with failures and try to handle errors by taking the right steps.
One of the most important things about microservices is that it's easier to handle bug fixes and new features because the services are smaller and can be deployed on their own. We can update a service without redeploying the whole app, and if something goes wrong, we can roll back an update.
If a bug is found in one part of a monolithic app, it can stop the whole process of releasing the app. So, new features had to wait until a bug was fixed before they could be added, tested, and made public.
A microservice should be small enough that it can be built, tested, and put into use by a single team. With the microservices model, a company can set up small, cross-functional teams that work on one service or a group of related services in an agile way. When we have a small team, we can move faster. Large teams tend to be less productive because they take longer to communicate and have more work to do. So when that happens, agility goes down.
Over time, a monolithic app's code base will grow so big that code dependencies will get tangled. Adding a new feature requires a lot of changes to the code that is already there. Since microservices don't share code or data stores with other services, dependencies are kept to a minimum. This makes it easier to add new features.
In traditional layered architectures, an application usually shares a single stack and is supported by a large relational database. This method has a few problems. For example, every part of an application must use the same stack, data model, and database, even if some modules could do their jobs better with a different tool. It's very frustrating for developers who know that there's a better, faster way to build these parts. Also, it's frustrating for developers when the application stack is too old and they can't use the best practices from newer projects on their own.
But with microservices architecture, small teams can choose the technology that works best for their microservice and use a mix of technology stacks on their services. Because microservices are set up separately and talk to each other using REST, event streaming, and message brokers. It is possible for each service to have a stack that is best for that service.
Technology is always changing, and development libraries and tools are also changing very quickly. Since an application is made up of several smaller services, it is much easier and cheaper to change it into a microservice with better technology.
Loose coupling between microservices also helps to separate faults and make applications more resilient. If one of our microservices stops working, the application as a whole won't be affected. Of course, we should make sure our microservices can handle errors and handle them in the right way, such as by using retry and circuit-breaking patterns. Even when things go wrong, if we fix them in a way that doesn't hurt our business, our customers will always be happy.
Microservices can be scaled up or down separately, so we can expand sub-services that use more resources without expanding the whole application. So, we can say that microservices need less infrastructure than monolithic apps because they let us scale only the services, we need instead of scaling the whole app.
Since microservices use the database-per-service pattern, databases are kept separate. Schema updates become easier because they only affect a single database. Schema updates can be very hard and risky in a single-piece application.
Microservices have a lot of pros, but they also have many cons. When we switch from a monolith to microservices, we have to manage a lot more things. Here are some of the problems we have to think about before we can use microservices architecture.
The services in a microservices application need to work together and make something of value. Since there are many services, there are more things that can go wrong than with a single application. Each service is easier to use, but the whole system is harder to understand.
Even deployments can be hard to manage when hundreds of services deploy at different times. Think about the way they communicate with each other. Components in a monolithic application can easily communicate with each other because it is inter-process communication, which means it can be the same machine and the same process. But communication between microservices is hard, and we need a plan to handle inter-service communications between servers or in different parts of the geo-locations.
Since microservices communicate with each other through inter-service communication and are small, we should manage network problems. If we call a chain of services for a specific request, this will cause latency issues, and APIs will need to be designed correctly for proper communication. To avoid chatty API calls. We should think about asynchronous communication patterns like message broker systems.
Think about the E2E process, which is one of the most important business needs. If the requirements involve several microservices that need to work as one application, it's harder to build and test these end-to-end (E2E) processes in a microservices architecture than in a monolithic architecture. Not all of the tools out there are made to work with service dependencies. It can be hard to refactor across service boundaries.
Each microservice has its own way of keeping data. So it can be hard to keep data consistent. Most of the time, we should try to be as consistent as possible. Transactional operations, on the other hand, will always be hard.
But these problems aren't stopping people from using microservices. Most organizations are willing to deal with these problems and are adapting their technologies to microservices architecture so they can get benefits from this architecture.
When we decide to replace a huge monolithic system with many microservices, the database is the most important thing. In a monolithic architecture, a big database is used in one place. In the beginning, developers might try keeping the database as it is, even when they move to microservice architecture. While it gives some short-term benefits, it is an anti-pattern, especially in a large-scale system, as the microservices will be tightly coupled in the database layer. A better way to do things is to give each microservice its own data store. This way, services don't have to be tightly linked in the database layer.

In a microservice architecture, where each microservice has its own database, the microservices need to share information. Systems that are reliable, scalable, and can handle mistakes should communicate with each other asynchronously by exchanging Events.
Use event-based architecture with event sourcing in this scenario. In traditional databases, the current "state" of the business entity is stored directly. In Event Sourcing, events that change the state of an entity or that are otherwise important are stored instead of the entities themselves. It means that changes to a business entity are saved as a series of events that can't be changed. By reprocessing all the Events of a business entity at a given time, the state of that business entity can be found. Since data is stored as a series of events instead of as direct updates to data stores, different services can replay events from the event store to figure out how their own data stores should be set up.

If we use event Sourcing, it will be hard to read data from the Event Store. We need to process all entity events in order to get an entity from the Datastore. Also, sometimes we have different needs for read and write operations when it comes to consistency and speed.
CQRS separates reads and writes into two different models. Commands are used to change data, while queries are used to read data.
We can physically separate the read data from the write data to keep them even more separate. In that case, the read database can use its own, query-optimized data schema. For example, it can store a materialized view of the data so that complex joins or ORM mappings don't have to be done. It might even store data in a different way. For example, the write database could be a relational database, while the read database could be a document database.

If we use microservice architecture with a database per microservice, it can be hard to keep everything consistent through distributed transactions. We can't use the traditional Two-phase commit protocol because SQL databases don't support it or it doesn't scale (many NoSQL Databases).
In Microservice Architecture, we can use the Saga pattern for distributed transactions. Saga is an old pattern that was created in 1987 as an alternative way to think about database transactions that take a long time to finish in SQL databases. But a newer version of this pattern works great for distributed transactions as well.
The Saga pattern is a local transaction sequence in which each transaction updates data in the Data Store within a single Microservice and publishes an Event or Message. The first transaction in a saga is initiated by an external request (Event or Action). Once the local transaction is done (data is stored in the Data Store and a message or event is published), the published message or event triggers the next local transaction in the Saga.
Most Saga transactions are coordinated in one of two ways:

BFF Architecture ensures the Backend and the Frontend applications are separated and decoupled into Services. It can communicate together via either API or GraphQL. If the app has both a mobile app and a web app, it would be hard to use the same backend Microservice for both of them. Most of the time, the API requirements for mobile apps and web apps are different because mobile apps have different screen sizes, displays, performances, energy sources, and network bandwidths.
BFF also has other benefits, like acting as a facade for downstream Microservices. This makes communication between the UI and downstream Microservices less chatty. Also, BFFs are used to increase security when downstream microservices are set up in a DMZ network, which is very safe.
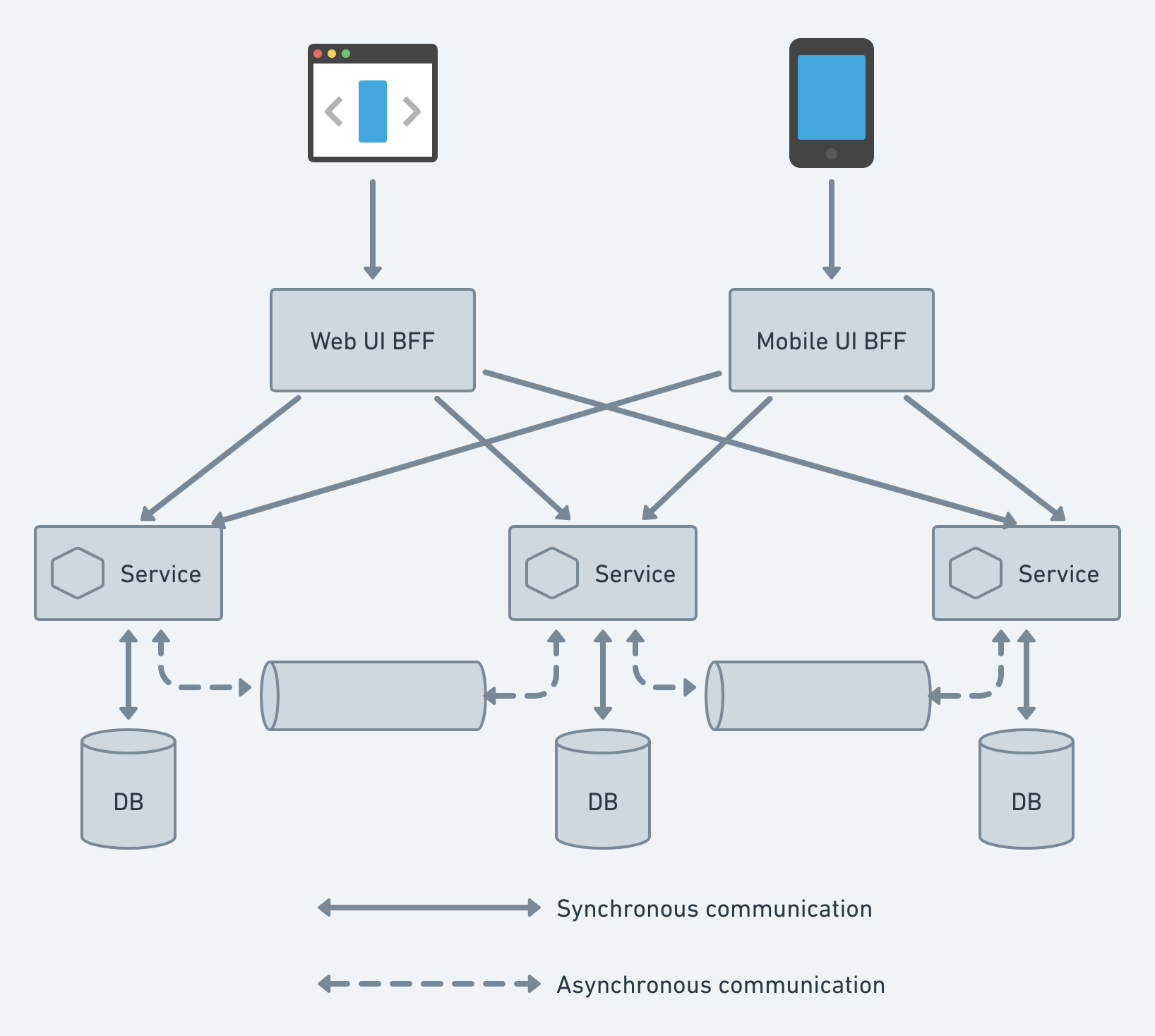
In Microservice Architecture, the user interface (UI) usually connects to more than one Microservice. If the Microservices are small (FaaS), the Client may need to connect to a lot of them, which can be noisy and difficult. Also, both the services and their APIs can change over time. Large businesses will have other issues that affect them all (SSL termination, authentication, authorization, throttling, logging, etc.).
API Gateway is such a way that might solve these problems. API Gateway is a facade that sits between the Client APP and the Backend Microservices. It can act as a reverse proxy and send the request from the Client to the right Backend Microservice. It can also send the client's request to multiple Microservices and return the responses from all of them to the Client. It also helps with important issues that cut across different areas.

If we want to use Microservice Architecture in a "brownfield project", we need to migrate the existing Monolithic applications to Microservices. Moving an existing, large, production-ready monolithic application to microservices is not easy because it could affect the availability of the application.
The Strangler pattern is a way to solve the problem. Strangler pattern means to move a Monolithic application to a Microservice Architecture by replacing certain functions with new Microservices over time. Also, new features are only added to Microservices, while the old Monolithic application stays the same. The requests are then sent between the legacy Monolith and the Microservices by setting up a Facade (API Gateway). Once the functionality is moved from the Monolith to the Microservices, the Facade will pick up the client request and send it to the new Microservices. Once all the functions of the legacy monolith have been moved, the legacy monolith application is "strangled".

In Microservice Architecture, where Microservices communicate to each other Synchronously, a Microservice will usually call other services to meet business needs. Calls to other services can fail because of temporary problems (slow network connection, timeouts, or temporal unavailability). In this case, retrying the call can fix the problem. But if there is a major problem (such as the Microservice not working at all), the Microservice will be down for a longer time. In these situations, retrying is useless and wastes valuable resources (the thread is blocked, which wastes CPU cycles). Also, if one service fails, it could cause failures in other parts of the application. In these situations, it's better to fail immediately.
In these kinds of situations, the Circuit Breaker pattern can save the day. A proxy that works like an electrical circuit breaker should be used for a Microservice to request another Microservice. The proxy should keep track of how many recent failures there have been and use that number to decide whether to let the operation continue or just throw an error immediately.
There are three possible states for the Circuit Breaker:

Because each microservice can be developed, deployed, and scaled independently by a business, microservices architecture enables increased agility and pluggability. However, microservices monitoring and management can be particularly challenging, given the need to track and maintain each service component of an application and its interactions.


